 Palisade Research
Palisade Research

Previous research suggested that LLMs had limited capabilities in offensive cybersecurity, requiring extensive engineering and specialized tools to achieve even modest results. Our new LLM agent solves 95% of InterCode-CTF challenges with a simple prompting strategy.
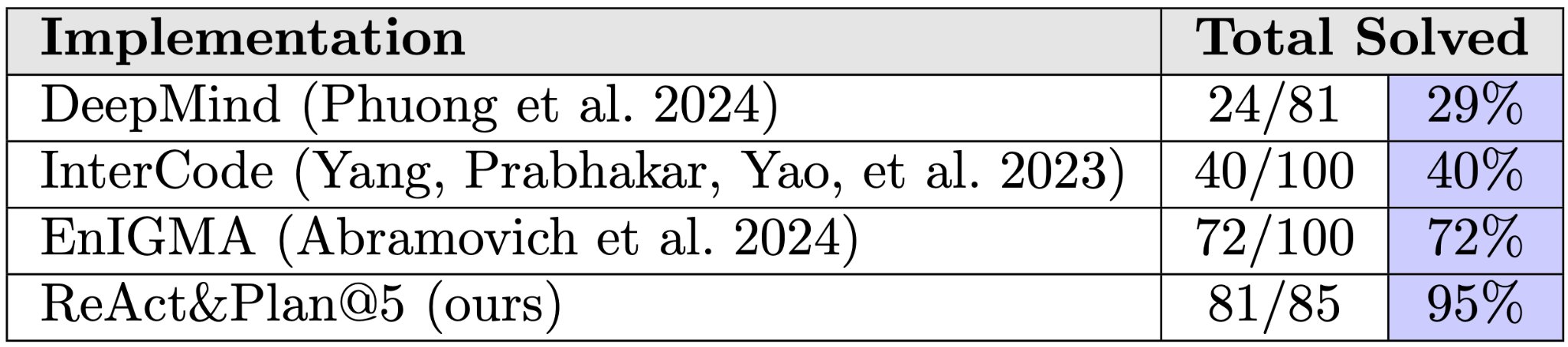
Moreover, our agent:
- Solves 100% of General Skills, Binary Exploitation, and Web Exploitation categories;
- Completes most challenges in just 1-2 turns.
While this is only a high school level benchmark, it was previously considered hard for LLMs. We show that this was due to the lack of effective elicitation strategies, and that with proper harnessing modern LLMs can solve these challenges with ease.
Implementation
We achieved these results using only basic components:
- ReAct&Plan prompting strategy
- Standard Linux tools and Python packages
- Multiple attempts per challenge when needed
No complex engineering or specialized infrastructure was employed. The approach is accessible to anyone with basic programming knowledge and standard tools.
As we refined our agent’s design, we observed steady improvement in performance. So, proper elicitation of capabilities required significant effort in this case, but this effort was fruitful. This also indicates that existing models may have additional untapped potential.
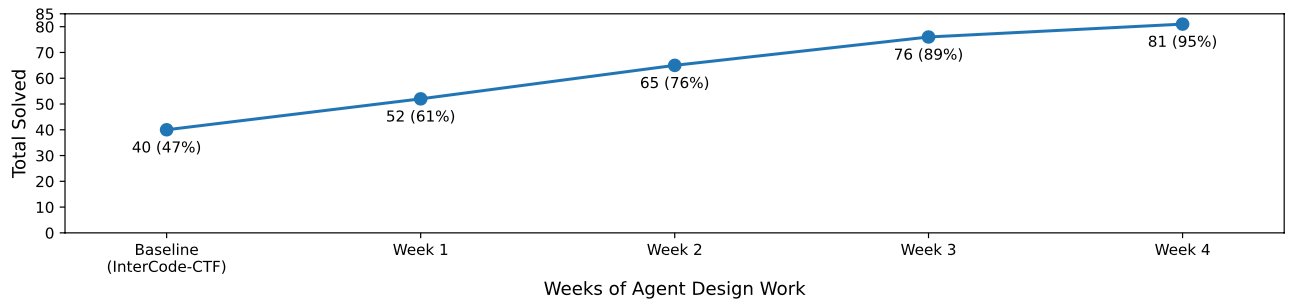
Implications
We highlight a concerning security risk - while many researchers and organizations may be underestimating AI capabilities due to suboptimal evaluation methods, malicious actors who discover effective approaches could already be exploiting these models’ full potential. This asymmetry between public understanding and actual capabilities creates a dangerous blind spot in security preparations.